
Monitoring Windows system metrics with Grafana
Published on:Table of Contents
Update: 2017-10-30: With new preferred graphite docker image
Update: 2017-11-01: I’ve opensourced a Windows utility that will export Open Hardware sensor data into Graphite. It adds GPU, power, temperature, and more, which won’t be covered in this post. Check it out! [The follow up post]({% post_url 2016-12-29-exporting-open-hardware-data-into-graphite %}) contains a little more context.
At work we’re using Grafana for realtime visualization dashboards. We recently started this work and have had a blast creating dashboards and teasing new insights from data. Last month, I attended Grafanacon 2016, and one of the themes is how prevalent Grafana has become; with screenshots of Microsoft, NASA, and Intel using Grafana dashboards in advertisements. Anyways, a coworker linked to a Grafana dashboard of someone’s Plex setup running ontop of ESXi.
{kind=link}
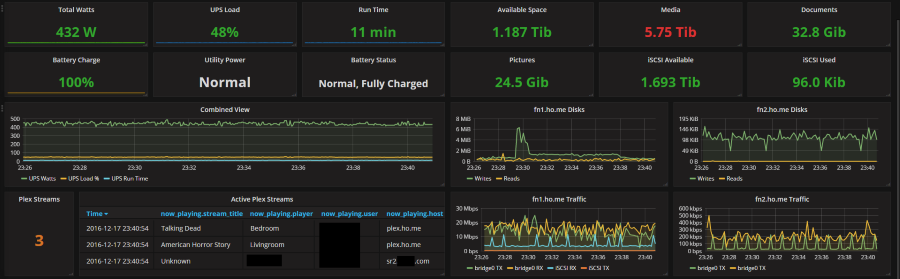
A screenshot of a home labber’s grafana dashboard
I run Hyper-v (I’ve written Linux Virtualization with a Mounted Window’s Share on Client Hyper-V) and don’t use plex, but I wanted to know if I could create a dashboard about my machine as well. Since Windows already publishes metrics via Performance Counters, I wanted to visualize them with Grafana. Here’s how we’ll do it:
- The host machine has performance counters
- Install the single binary, time series data collector, telegraf onto the host.
- Run Graphite within a docker container on virtual machine.
- Install Grafana onto virtual machine.
This may be overcomplicating things, as both docker and Grafana can be installed on Windows. Indeed, docker contains thorough information for Windows users. But I like to keep my host machine as clean as it can be and I still feel like docker and Grafana treat Windows as a second class citizen citation needed
Telegraf
After downloading the Telegraf Windows bundle, the default config is pretty good, but could use some updating for my use case. Below is the config that I’m currently using:
# Telegraf configuration
# Configuration for telegraf agent
[agent]
## Default data collection interval for all inputs
interval = "5s"
## Rounds collection interval to 'interval'
## ie, if interval="10s" then always collect on :00, :10, :20, etc.
round_interval = true
## Telegraf will cache metric_buffer_limit metrics for each output, and will
## flush this buffer on a successful write.
metric_buffer_limit = 1000
## Flush the buffer whenever full, regardless of flush_interval.
flush_buffer_when_full = true
## Default flushing interval for all outputs. You shouldn't set this below
## interval. Maximum flush_interval will be flush_interval + flush_jitter
flush_interval = "5s"
## Run telegraf in quiet mode
quiet = false
## Specify the log file name. The empty string means to log to stdout.
logfile = "D:/logs/telegraf.log"
## Override default hostname, if empty use os.Hostname()
hostname = ""
###############################################################################
# OUTPUTS #
###############################################################################
# Configuration for Graphite server to send metrics to
[[outputs.graphite]]
servers = ["192.168.137.201:2003"]
prefix = ""
template = "measurement.tags.field"
timeout = 2
###############################################################################
# INPUTS #
###############################################################################
[[inputs.win_perf_counters]]
[[inputs.win_perf_counters.object]]
# Processor usage, alternative to native, reports on a per core.
ObjectName = "Processor"
Instances = ["*"]
Counters = [
"% Idle Time",
"% Interrupt Time",
"% Privileged Time",
"% User Time",
"% Processor Time",
]
Measurement = "win_cpu"
# Set to true to include _Total instance when querying for all (*).
IncludeTotal=true
[[inputs.win_perf_counters.object]]
# Disk times and queues
ObjectName = "LogicalDisk"
Instances = ["*"]
Counters = [
"Free Megabytes",
"Disk Reads/sec",
"Disk Writes/sec",
"Disk Bytes/sec",
"% Idle Time",
"Current Disk Queue Length",
]
Measurement = "win_disk"
# Set to true to include _Total instance when querying for all (*).
#IncludeTotal=false
[[inputs.win_perf_counters.object]]
ObjectName = "Network Interface"
Counters = [
"Bytes Sent/sec",
"Bytes Received/sec",
]
Instances = ["*"]
Measurement = "win_network"
[[inputs.win_perf_counters.object]]
# Example query where the Instance portion must be removed to get data back,
# such as from the Memory object.
ObjectName = "Memory"
Counters = [
"Available Bytes",
"Committed Bytes",
"Cache Bytes",
"Pages/sec",
"Pool Nonpaged Bytes",
"Pool Paged Bytes",
]
# Use 6 x - to remove the Instance bit from the query.
Instances = ["------"]
Measurement = "win_mem"
# Set to true to include _Total instance when querying for all (*).
#IncludeTotal=false
Notes:
- Collection interval set to 5s as the default of 10s seems too slow and values smaller than 5s tend to timeout gathering the metrics.
- Moved logfile to my
D:drive as myC:drive is fast SSD and it’s not worth storing logs. - The one output is our graphite instance running on our VM. There may be something wrong with Go’s (the language that telegraf is written in) domain name resolution as only the IP address worked.
- The graphite template removes the
hostsegment and swapsmeasurementwithtags, asmeasurementwill be something likewin_diskand one of the tags will beC:. The one thing I dislike with telegraf’s data output is that I can’t choose to filter out tags, so even useless tags get written to graphite - I
IncludeTotalfor processors as it gives a good overview of processor usage across all processors, which is convenient for calculations and also helpful if the number of processors ever change. - For
LogicalDisk, I prefer seeing the disk throughput instead of percentages - Remove
Systemperformance metrics. I don’t think there is a use for these metrics for average computer user. - For
MemoryI prefer to see how many committed bytes as well as available bytes
Service
Running it at the commandline is fine for testing, but having telegraf boot up
on start up is ideal. Telegraf provides a way to install as a
service. Since I install telegraf into C:\Apps\telegraf, I executed the service command like the following:
.\telegraf.exe --config C:\Apps\telegraf\telegraf.conf --service install
Graphite
Update: 2017-10-30: My new favorite graphite docker image is the official
one
graphiteapp/graphite-statsd,
so installation may be a little different. Also I removed the configuration
that started graphite on boot (it is handled natively by docker using the
restart command line)
Next comes Graphite and it’s bad rap for being hard to install. Yes, a lot of it is rooted in truth and work needs to be done to make installation easier, but people tend to make mountains out of mole hills. If one makes technical decisions solely on difficulty of installations, then they’d be missing out. Instead, we’re just going to use docker setup our instance. My favorite graphite installation is praekeltfoundation/graphite because it doesn’t come with a significant amount of unneeded programs. The only thing we need to change is the data retention policy; we want store data at the five second level, and not minutely.
docker run praekeltfoundation/graphite --name init_graphite
docker exec -it init_graphite sed -i -e 's/1m:1d/5s:1d/' conf/storage-schemas.conf
docker commit init_graphite my_graphite
Now that we have our image, let’s boot it up!
docker run -p 2003:2003 -p 8000:8000 \
-v /home/nick/docker/graphite:/opt/graphite/storage \
--restart "unless-stopped" \
--name graphite_server my_graphite
- We expose port 2003, which is the inbound port for metrics data
- Also port 8000 so grafana can talk to the graphite render api
Grafana
Grafana is the easiest step.
- Follow the install instructions
- Login with admin, admin
- Add graphite as a datasource
- Start visualizing
Result
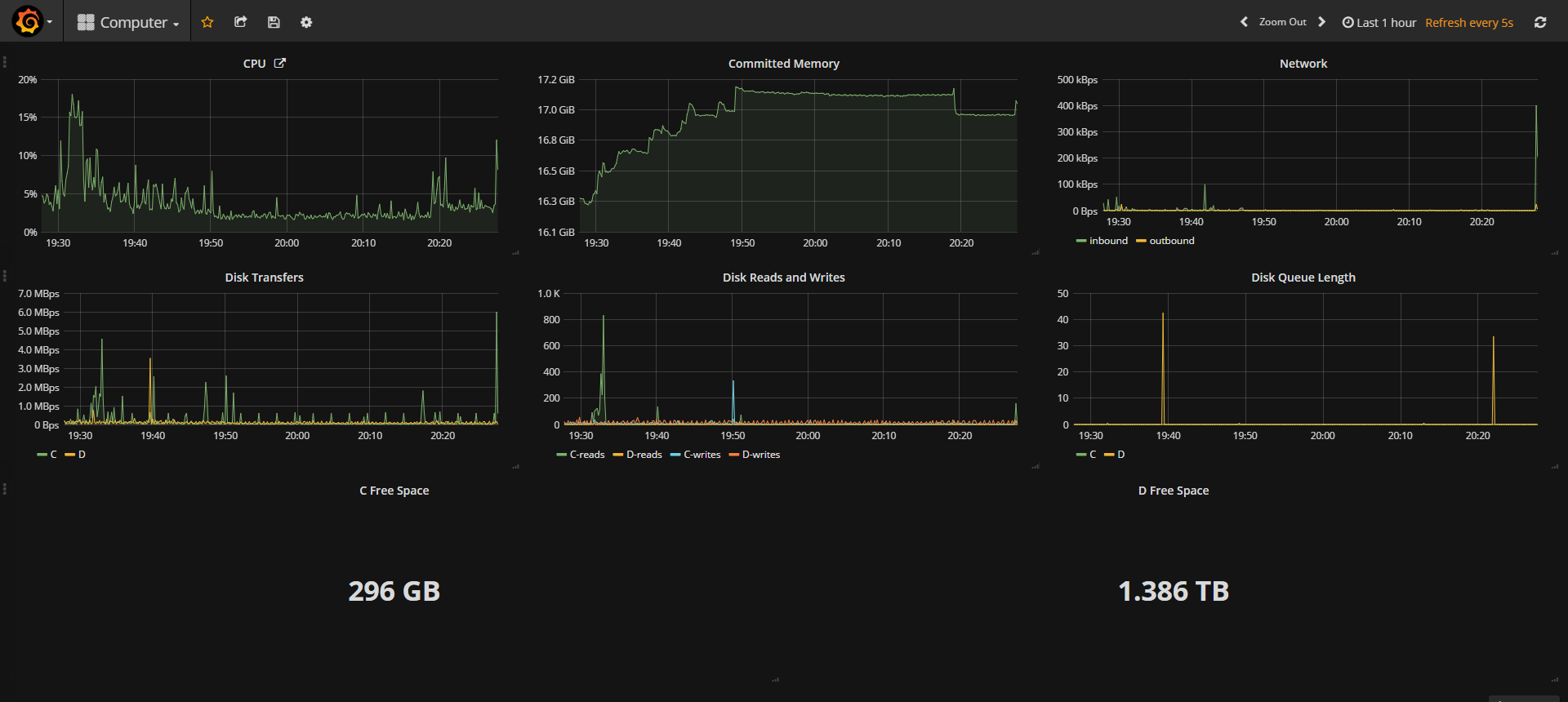
Resulting Grafana Dashboard
Future
- Hardware temperature
- GPU metrics
These two will probably require information outside of telegraf. I’m hoping to hitch a ride off Open Hardware Monitor.
See the follow up post for how to include GPU, temperature and power metrics.
Comments
If you'd like to leave a comment, please email hi@nickb.dev
Great Tutorial! The only thing I’m trying to get under LogicalDisk is ‘Used Space’ as opposed to ‘Free Space’ as I want to set thresholds in SingleStat. Any idea how to get that?
I was able to figure it out by adding a calculation to the beginning of the query. We have a 120Gb C: drive so I added the total space and minussed it. “ SELECT 122877.996094 - “Free_Megabytes’ FROM….etc ” This gave me the figure I was looking for.
This is fantastic! My question though is how do you pull your UPS data? I have 2 Cyberpower UPS’ that I parse data from, which works OK. However, when utility power is off, grafana doesn’t report and changes. It appears as though no info is being received, as the battery capacity might be 82%, but grafana will continue to report 100%. However, once power is restored and the battery is charging, it’ll read the correct reading. I’ve also been unsuccessful in getting the Utility Power and Battery Status from mine. Would you mind sharing how you’ve pulled the info from your UPS and got it to work in grafana? Thanks!
The screenshot you’re thinking of is actually from a linked imgur post. Sadly, I lost the reddit discussion for it, but someone else wrote Setup a wicked Grafana Dashboard to monitor practically anything that details how to capture UPS data
Fantastic article, I have Graphite running from the newer docker image you posted ( graphiteapp/graphite-statsd), grafana I installed from the CentOS repo on their website.
I used openhardware monitor, your ohm app and telegraf on an Alienware laptop running Windows 10 fall update and managed to get data out of it so: https://imgur.com/a/8oabGkb
Hi, could you please share the change needs to be done in the config file to get the CPU usage for individual core? i made “include all” to false and blank but no luck